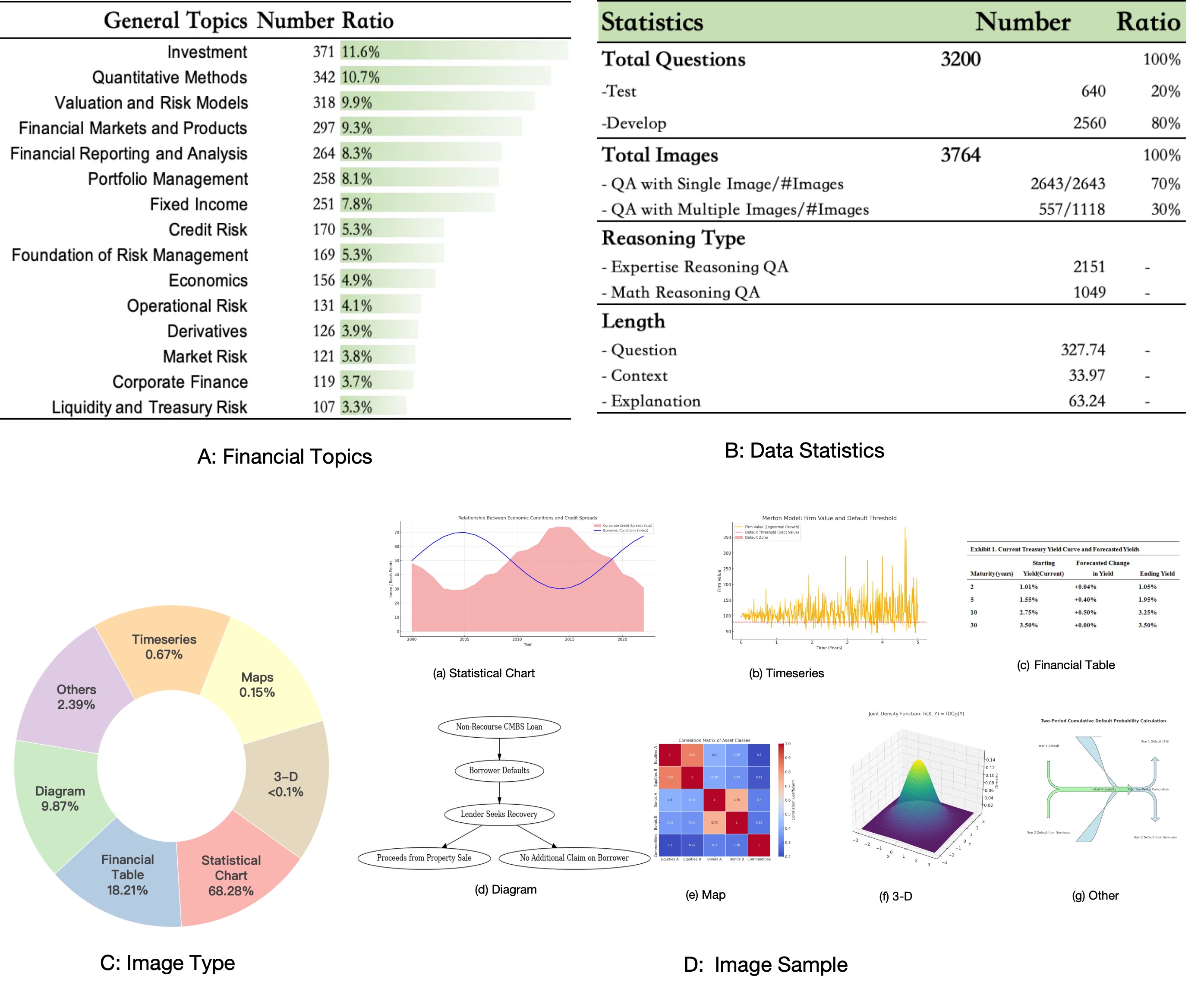
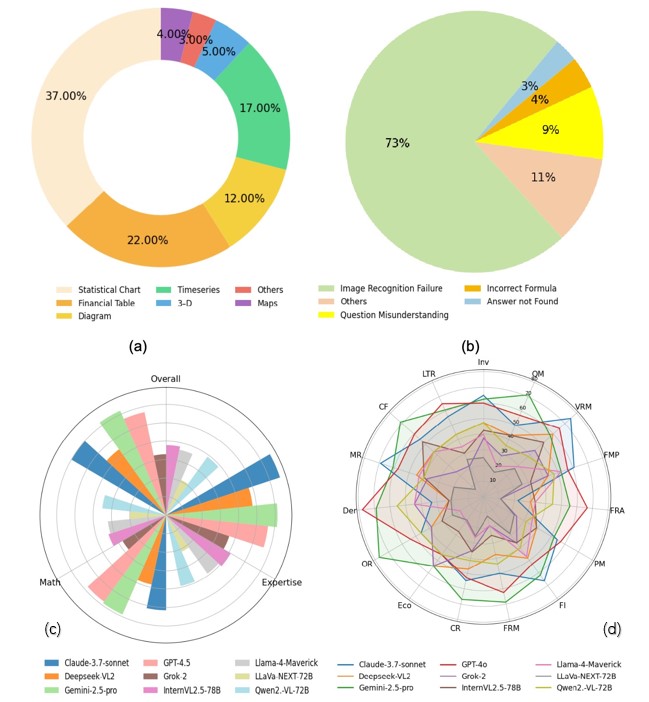
Multimodal Large Language Models (MLLMs) have made substan tial progress in recent years. However, their rigorous evaluation withinspecializeddomainslikefinanceishinderedbytheabsenceof datasets characterized byprofessional-level knowledgeintensity,de tailed annotations, and advanced reasoning complexity. To address this critical gap, we introduce FinMR, a high-quality, knowledge intensive multimodal dataset explicitly designed to evaluate expert level financial reasoning capabilities at a professional analyst’s standard. FinMR comprises over 3,200 meticulously curated and ex pertly annotated question-answer pairs across 15 diverse financial topics, ensuring broad domain diversity and integrating sophisti cated mathematical reasoning, advanced financial knowledge, and nuanced visual interpretation tasks across multiple image types. Through comprehensive benchmarking with leading closed-source and open-source MLLMs, we highlight significant performance disparities between these models and professional financial ana lysts, uncovering key areas for model advancement, such as precise image analysis, accurate application of complex financial formu las, and deeper contextual financial understanding. By providing richly varied visual content and thorough explanatory annotations, FinMR establishes itself as an essential benchmark tool for assessing and advancing multimodal financial reasoning toward professional analyst-level competence.

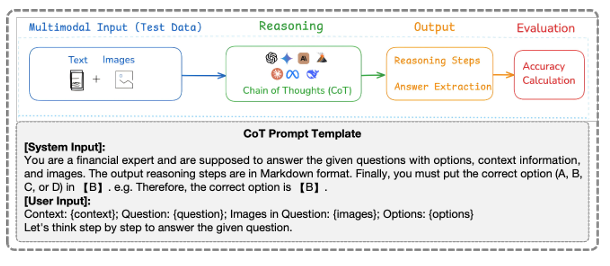
Two example questions
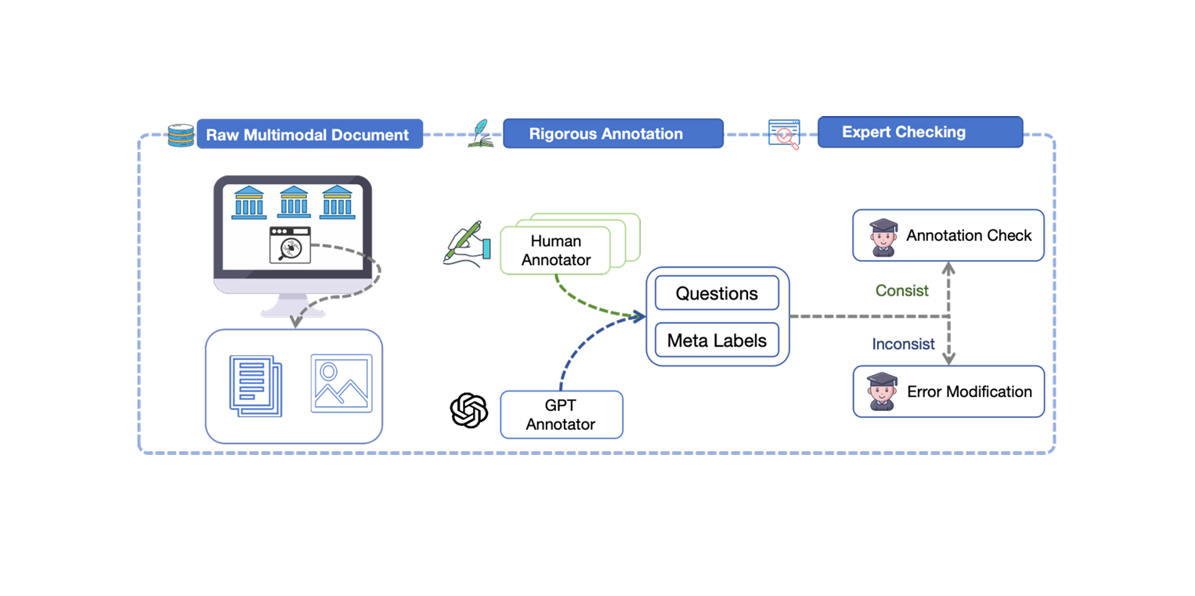
The annotation pipeline of FinMR
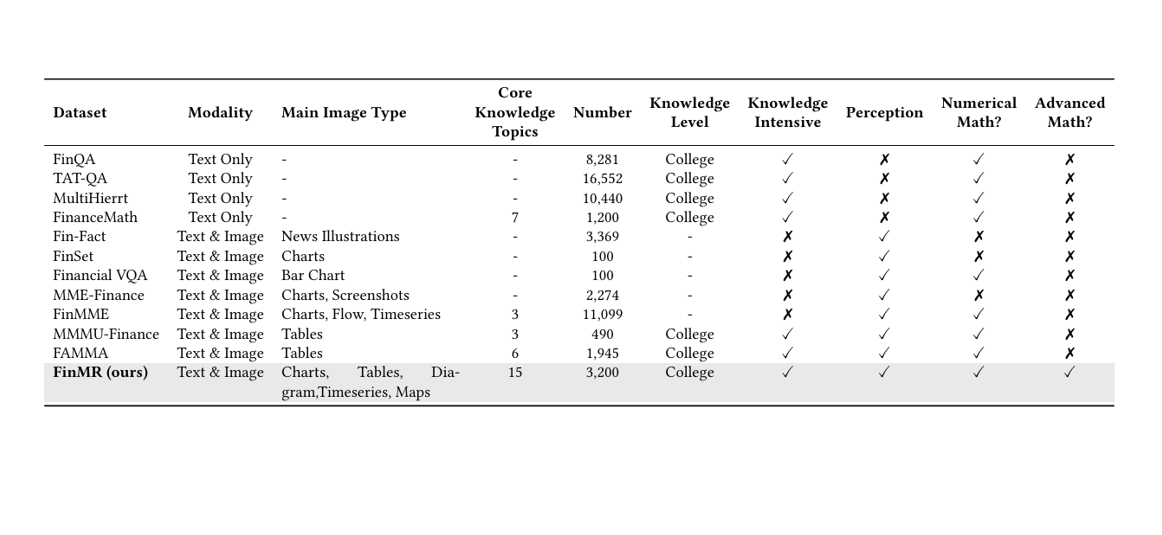
Comparison of FinMR with existing financial reasoning benchmarks